Étude de l’agrégation de lecture / écriture pour exploiter les opportunités de réduction de puissance à l’aide de tensions d’alimentation doubles (projet électronique)
- in Autre Projet
->
ABSTRAIT
La consommation d’énergie joue aujourd’hui un rôle important dans la conception des systèmes informatiques. Les structures de mémoire sur puce telles que le cache à plusieurs niveaux représentent une proportion importante de la consommation totale d’énergie du processeur ou de l’application spécifique intégrée Circuit (AISC), spécialement pour les applications gourmandes en mémoire, telles que le calcul en virgule flottante et l’algorithme d’apprentissage automatique. Par conséquent, il existe une motivation claire pour réduire la consommation d’énergie de ces structures de mémoire qui sont principalement constituées de blocs de mémoire à accès aléatoire statique (SRAM). Dans cette défense, je présenterai le cadre d’un nouveau schéma de tension d’alimentation double qui utilise des niveaux de tension séparés pour les opérations de lecture et d’écriture en mémoire.
En analysant quantitativement la trace du cache pour les tests de performances SPEC2000, Parsec et Cortexsuite et en comparant la caractérisation de la séquence de lecture / écriture de différents types d’applications informatiques, je découvre que les applications gourmandes en mémoire ont un potentiel élevé pour générer de longues séquences de lecture / écriture consécutives, qui peuvent être exploitées. par notre proposition de double cadre d’approvisionnement. J’effectue ensuite une étude des limites basée sur une réorganisation en lecture / écriture idéale pour obtenir l’estimation d’économie d’énergie maximale possible. Enfin, en tant qu’étude de cas, j’applique ce cadre à une conception d’accélérateur ASIC d’apprentissage automatique personnalisé pour montrer sa viabilité.
CONTEXTE
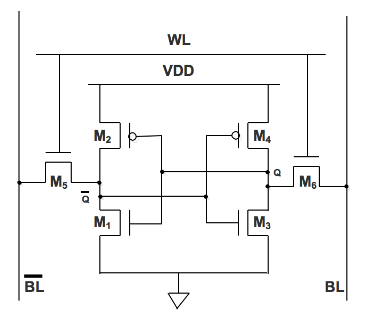
Figure 2.1 SRAM 6T
SRAM peut conserver ses informations stockées tant que l’alimentation est fournie. La structure d’une cellule SRAM 6-T, stockant un bit d’information, est illustrée à la figure 2.1. Le cœur de la cellule est formé de deux onduleurs CMOS, où le potentiel de sortie de chaque onduleur Ven dehors est alimenté en entrée dans l’autre Vdans. Cette boucle de rétroaction stabilise les onduleurs dans leur état respectif. Les transistors d’accès et les lignes de mots et de bits, Ligne de mots (WL) et Ligne de bits (BL), sont utilisés pour lire et écrire depuis ou vers la cellule. En mode veille, la ligne de mots est faible, ce qui désactive les transistors d’accès.
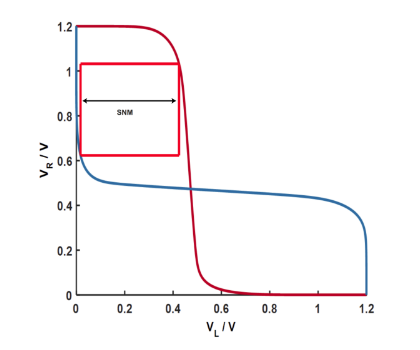
Figure 2.2 SNM
La marge de bruit statique (SNM) est une évaluation importante de la stabilité des cellules SRAM. Il peut être extrait en imbriquant le plus grand carré possible dans les deux courbes de transfert de tension (VTC) des onduleurs CMOS concernés, comme le montre la figure 2.2. Sur cette figure, VR signifie la tension du transistor droit M6 et VL signifie la tension du transistor gauche M5.
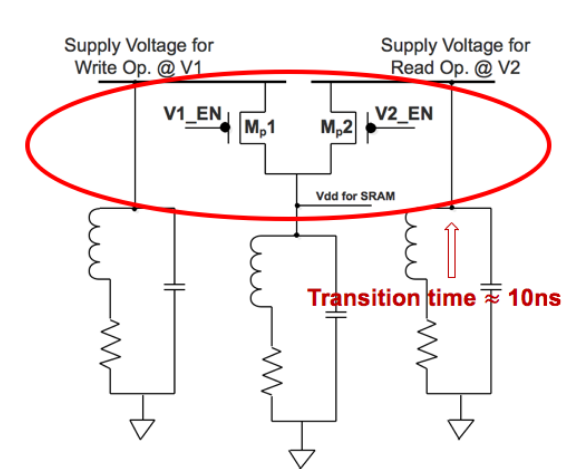
Figure 2.7 Circuit de commutation de tension rapide au niveau du cœur
Afin de séparer l’alimentation en tension pour les opérations de lecture et d’écriture respectivement, nous référons le circuit de commutation de tension rapide au niveau du cœur illustré à la figure 2.7 à partir du Booster Comme le montre la figure 2.7, si V1_EN est défini sur 1 et V2_EN est défini sur 0, alors Mp1 ON et Mp2 OFF, le commutateur VDD pour SRAM fournit la tension pour l’opération d’écriture @ V1. Au contraire, si V1_EN est mis à 0 et V2_EN est mis à 1, alors Mp1 OFF et Mp2 ON, puis VDD pour le commutateur SRAM pour fournir la tension pour l’opération de lecture @ V2.
ÉTUDE LIMITE
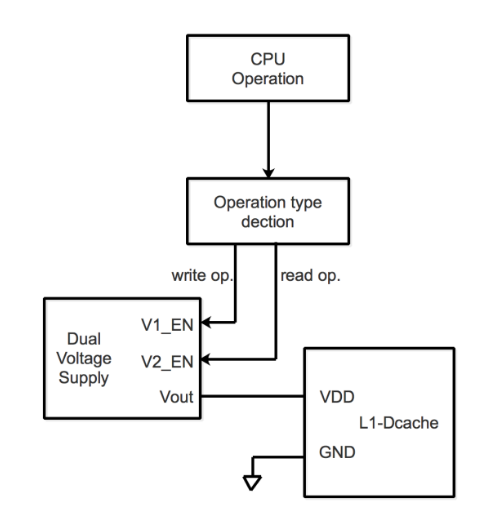
Figure 3.1 Schéma de commutation à double tension d’alimentation
Le cas idéal est que nous supposons que le circuit de commutation de tension rapide de niveau de noyau Booster ne coûtera rien. De sorte que nous commutons agressivement la double alimentation en tension sur V1 une fois qu’il y a une seule opération d’écriture, puis la commutons sur V2 une fois qu’il y a une seule opération de lecture, comme le montre la figure 3.1.
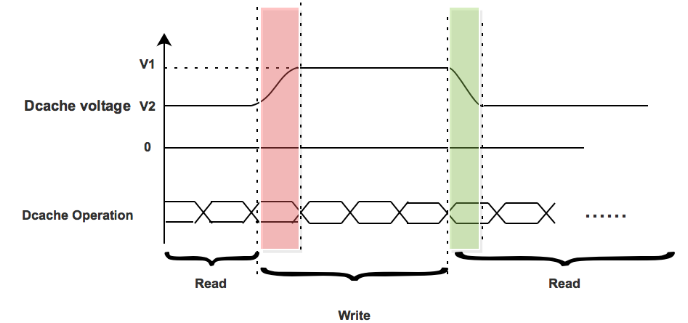
Figure 3.3 Analyse des pénalités de retard
Lorsqu’il y a une opération d’écriture, ce qui est illustré dans la zone rouge de la figure 3.3. Les deux tensions d’alimentation passent de V2 à V1. Mais il y a un retard de près de 10ns à chaque passage de V2 à V1. Avant que la tension d’alimentation n’atteigne V1, l’opération d’écriture doit être maintenue car la plage de tension de V2 à V1 n’est pas fiable pour l’opération d’écriture. Il y a donc une pénalité de retard lorsque les tensions d’alimentation doubles passent de V2 à V1.
Cependant, quand survient une opération de lecture illustrée dans la zone verte de la figure 3.3. Les tensions d’alimentation doubles passeront de V1 à V2. Dans cette plage de tension de V1 à V2, il est toujours fiable pour un fonctionnement en lecture. Par conséquent, l’opération de lecture n’a pas à rester en veille lorsque les tensions d’alimentation doubles commutent. Il n’y a pas de pénalité de retard lorsque les tensions d’alimentation doubles passent de V1 à V2.
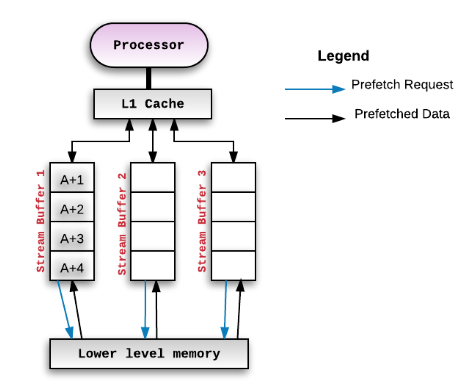
Figure 3.8 Cache de prélecture des tampons de flux
Dans la figure 3.8, il existe plusieurs tampons de flux entre le cache L1 et la mémoire de niveau inférieur. Le principal objectif de cette structure est de traiter la latence d’accès à la mémoire. Étant donné que les tampons de flux préliront à l’avance les données qui pourraient être utilisées dans un avenir proche. Il semble que cela pourrait nous aider à prédire la prochaine opération de lecture et d’écriture. Cependant, les données dans le tampon de flux ne sont pas exactement les données qui seront fermement utilisées pour être accessibles par le cache L1.
ÉCRIRE LE TAMPON D’AGRÉGATION
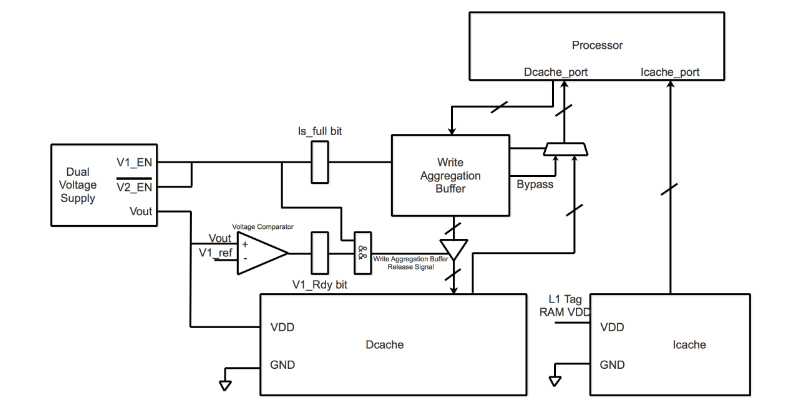
Figure 4.1 Structure du tampon d’agrégation d’écriture
Afin de réduire les temps d’accès L1-Dcache et de générer une longue séquence de lecture consécutive, nous proposons un tampon d’agrégation d’écriture comme le montre la figure 4.1. Ce tampon d’agrégation d’écriture regroupera les différentes opérations d’écriture ensemble, essayez d’empêcher l’opération d’écriture d’interrompre la longue lecture consécutive séquence.
Et il peut réduire les accès totaux en lecture et en écriture en raison du contournement de la lecture et du mécanisme de mise à jour automatique des données d’écriture de la même adresse. De plus, cette structure de tampon d’agrégation d’écriture fournira aux commutateurs à double tension d’alimentation une logique de commande. De la figure 4.1, nous pouvons conclure que la façon dont le tampon d’agrégation d’écriture, le commutateur de tensions d’alimentation double L1-Dcache, L1-Icache et le processeur sont intégrés ensemble.
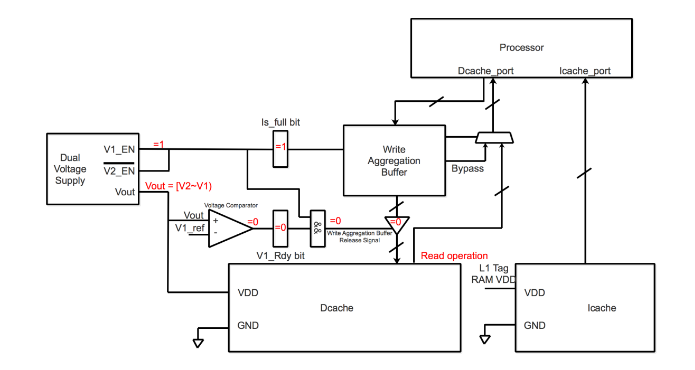
Figure 4.3 Valeurs / état de chaque registre ou composant de la structure du tampon d’agrégation d’écriture dans la tranche de temps de la zone rouge
Pour l’intervalle de temps de la zone rouge, les valeurs / état de chaque registre et composant dans la structure de tampon d’agrégation d’écriture sont présentés dans la figure 4.3. Lorsque le tampon d’agrégation d’écriture est plein, le bit Is_full est défini sur 1, puis V1_EN est défini sur 1 et les commutateurs de tensions d’alimentation doubles commutent la tension de V2 à V1. Cependant, il existe un retard d’environ 10 ns lorsque Vout passe de V2 à V1. La zone rouge indique l’intervalle de temps que Vout n’a pas atteint à V1. Dans cet intervalle de temps, V1_Rdy est toujours remis à 0.
Parce qu’il existe un comparateur de tension qui compare Vout à V1, si Vout =! Le bit V1, V1_Rdy est réinitialisé à 0. De sorte que dans l’intervalle de temps de la zone rouge, l’accès est toujours en opération de lecture car le bit V1_Rdy est toujours défini sur 0, puis le signal de libération du tampon d’agrégation d’écriture est toujours défini sur 0, ce qui rend l’opération d’écriture impossible. à ce créneau horaire. Et la plage de tension de V2 à V1 est toujours fiable pour la lecture. Par conséquent, L1-Dcache n’a pas à attendre pour que Vout atteigne V1, il n’y a pas de pénalité de retard ici.
ÉTUDE DE CAS
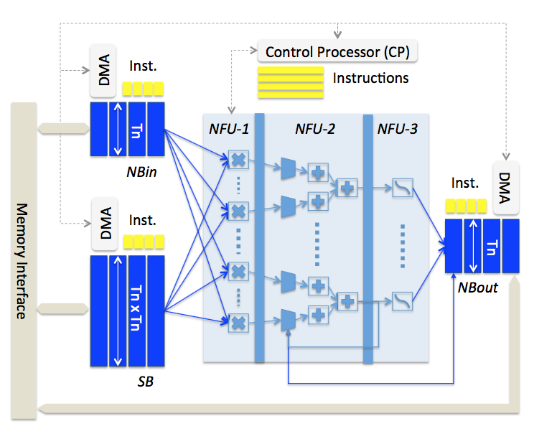
Figure 5.1 Architecture d’accélérateur DianNao
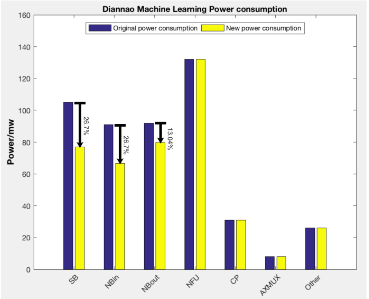
Figure 5.2 Économie d’énergie approximative à l’aide de deux tensions d’alimentation dans l’accélérateur DianNao
La figure 5.1 montre l’architecture de l’accélérateur DianNao. Combinez l’architecture de cet accélérateur, l’ensemble de données qu’ils ont utilisé pour cet accélérateur d’apprentissage automatique et la table d’instructions de contrôle. Nous pouvons approximer l’économie d’énergie montrée dans la figure 5.2 de SB, NBin et NBout en utilisant des tensions d’alimentation doubles. SB économise environ 26,7% de puissance, NBin réduit la puissance d’environ 26,7% et NBout réduit légèrement la puissance de 13,04%. Parce que NBout est utilisé pour le tampon pour enregistrer le résultat intermédiaire de ce réseau d’apprentissage automatique.
TRAVAIL FUTUR
Le tampon d’agrégation d’écriture est similaire à la file d’attente de stockage dans le processeur et est également très similaire au tampon de stockage dans Intel Haswell Arch. De sorte que nous aimerions les fusionner ensemble pour réduire la consommation d’énergie supplémentaire. Parce que construire une nouvelle architecture tampon est une sorte de compromis. Lorsque nous construisons un nouveau composant, il entraînera d’autres coûts d’énergie, tels que la consommation d’énergie logique logique combinatoire. Par conséquent, la fusion de la conception devrait être le meilleur moyen d’équilibrer ce problème.
Deuxièmement, notre tampon d’agrégation d’écriture brisera la localité spatiale d’une manière ou d’une autre. Mais c’est une sorte de compromis entre puissance et performance. Nous prévoyons de rejouer la nouvelle trace de cache avec le tampon d’agrégation d’écriture sur l’interface de relecture gem5 et d’analyser comment ces paramètres seront affectés si nous utilisons ce type d’agrégation d’écriture. Enfin, nous attendons toujours de trouver des indices solides pour prédire la séquence de lecture et d’écriture. Ce n’est peut-être pas un travail facile. Cependant, si nous atteignons cette destination, nous aurons plus d’occasions de réduire la puissance en utilisant des tensions d’alimentation doubles.
CONCLUSIONS
Dans cette thèse, nous réduisons la consommation d’énergie du cache en utilisant une double alimentation, ce qui fait que les caches fonctionnent à des tensions inférieures en état de lecture et fonctionnent à haute tension en état d’écriture. Nous utilisons gem5 et McPAT pour analyser les fuites et la panne d’alimentation dynamique du processeur, et concluons que le cache consomme une grande partie de la consommation totale d’énergie.
Nous utilisons gem5 pour faire la trace du cache de L1Dcache en fonction de différents types de références. Conclure que différents tests de référence ont une caractérisation de trace de cache différente. Les benchmarks d’apprentissage automatique sont généralement des applications gourmandes en mémoire et SPEC2000 sont des calculs intensifs.
Nous proposons un tampon d’agrégation d’écriture pour regrouper les opérations d’écriture afin de générer une longue séquence de lecture consécutive, ce qui augmentera les possibilités de réduction de puissance en utilisant une alimentation double tension. Nous faisons une étude de cas pour apprendre que l’alimentation double tension devrait réduire la consommation d’énergie de SRAM dans la puce ASIC plus efficacement.
Source: Université de Washington
Auteur: Gu Yunfei